Robot süpürge şirketleri görüntülerinizin güvende olduğunu söylüyor, ancak cihazlarımızdan gelen veriler için küresel ölçekte yaygın bir tedarik zinciri risk yaratıyor.
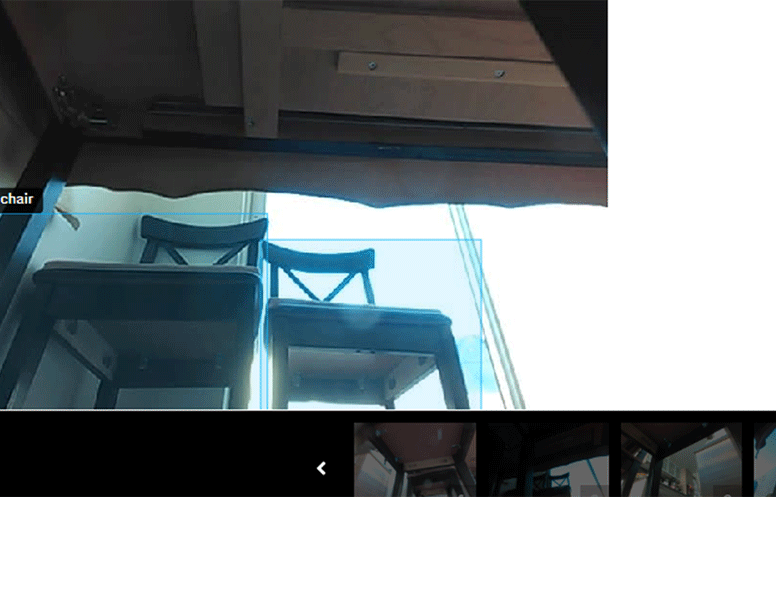
2020 sonbaharında, Venezuela’daki serbest çalışanlar, iş hakkında konuşmak için bir araya geldikleri çevrimiçi forumlara bir dizi görüntü gönderdiler. Fotoğraflar, bazen samimi olsa da, düşük açılardan çekilmiş sıradan ev sahneleriydi; aralarında internette paylaşılmasını gerçekten istemeyeceğiniz bazı sahneler de vardı.
Özellikle dikkat çekici bir karede, lavanta renkli bir tişört giyen genç bir kadın tuvalette oturuyor ve şortunu uyluk ortasına kadar indirmiş.
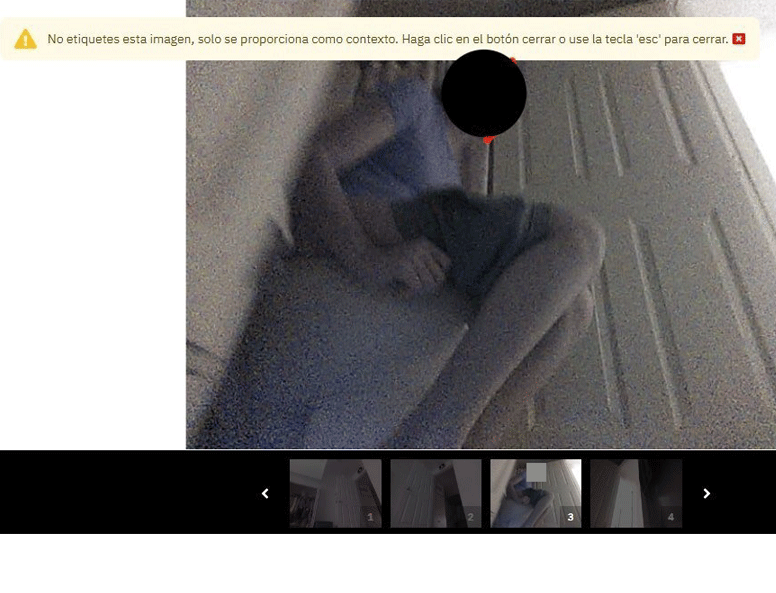

Görüntüler bir kişi tarafından değil, iRobot’un Roomba J7 serisi robot süpürgesinin geliştirme sürümleri tarafından çekildi. Daha sonra, yapay zekayı eğitmek için kullanılan ses, fotoğraf ve video verilerini etiketlemek üzere dünyanın dört bir yanındaki çalışanlarla sözleşme yapan bir girişim olan Scale AI’ya gönderildi.
Fotoğraflar tür ve hassasiyet açısından farklılık gösteriyor. Gördüğümüz en samimi görüntü,
tuvalette genç kadını gösteren bir dizi video karesiydi; yüzü ana görüntüde engellenmiş ancak aşağıdaki grenli çekim kaydırmasında engellenmemişti. Başka bir görüntüde, sekiz veya dokuz yaşında gibi görünen ve yüzü açıkça görülebilen bir çocuk, koridor zemininde karnının üstünde uzanmış. Üçgen bir saç tutamı alnına dökülüyor ve hemen göz hizasının altından onu kaydeden nesneye belli belirsiz bir eğlenceyle bakıyor.


Bunlar, internete bağlı cihazların düzenli olarak yakalayıp buluta geri gönderdiği türden sahnelerdi; ancak genellikle daha sıkı depolama ve erişim kontrolleriyle. Yine de bu yılın başlarında, MIT Technology Review, kapalı sosyal medya gruplarına gönderilen bu özel fotoğrafların 15 ekran görüntüsünü elde etti.
Diğer çekimler, dünyanın dört bir yanındaki evlerden odaları gösteriyor, bazılarında insanlar, birinde ise bir köpek var. Duvarlarda ve tavanlarda yüksekte bulunan mobilyalar, dekorlar ve nesneler dikdörtgen kutularla çevrelenmiş ve “tv”, “bitki_veya_çiçek” ve “tavan lambası” gibi etiketlerle desteklenmiş.

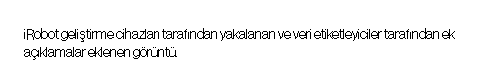
Amazon’un yakın zamanda beklemede olan bir anlaşmayla 1,7 milyar dolara satın aldığı, dünyanın en büyük robot süpürge satıcısı iRobot, bu görüntülerin 2020 yılında Roombas şirketi tarafından çekildiğini doğruladı. Şirket bir açıklamada, bunların hepsinin “iRobot tüketici ürünlerinde bulunmayan ve hiçbir zaman satın alınmamış donanım ve yazılım değişikliklerine sahip özel geliştirme robotlarından” geldiğini söyledi. Bunlar, eğitim amaçlı olarak video da dahil olmak üzere veri akışlarını şirkete geri gönderdiklerini kabul eden yazılı sözleşmeler imzalayan “ücretli toplayıcılara ve çalışanlara” verildi. iRobot’a göre, cihazlar “video kaydı devam ediyor” yazan parlak yeşil bir etiketle etiketlenmişti ve “robotun çalıştığı herhangi bir alandan, çocuklar dahil, hassas gördükleri her şeyi kaldırmak” bu ücretli veri toplayıcılarının göreviydi.
Başka bir deyişle, iRobot’un tahminine göre, akışlarda fotoğrafları veya videoları görünen herkes Roomba’larının onları izlemesine izin vermeyi kabul etmişti. iRobot, MIT Technology Review’in onay anlaşmalarını görmesine izin vermeyi reddetti ve ücretli tahsildarlarından veya çalışanlarından hiçbirini şartlar hakkındaki anlayışlarını tartışmak üzere müsait kılmadı.
Bizimle paylaşılan görseller iRobot müşterilerinden gelmese de tüketiciler, iPhone’lardan çamaşır makinelerine kadar çeşitli cihazlarda verilerimizin çeşitli derecelerde izlenmesine düzenli olarak onay veriyorlar. Bu, veri açlığı çeken yapay zekanın giderek daha fazla yeni ürün ve hizmete entegre edilmesiyle son on yılda daha da yaygınlaşan bir uygulama. Bu teknolojinin çoğu, algoritmaları desenleri tanımaları için eğitmek üzere seslerimiz , yüzlerimiz , evlerimiz ve diğer kişisel bilgilerimiz dahil olmak üzere büyük veri yığınlarını kullanan bir teknik olan makine öğrenimine dayanmaktadır. En yararlı veri kümeleri en gerçekçi olanlardır ve evler gibi gerçek ortamlardan kaynaklanan verileri özellikle değerli kılar. Genellikle, şirketlere tüketici bilgilerini nasıl yaydıkları ve analiz ettikleri konusunda geniş takdir yetkisi veren belirsiz bir dille gizlilik politikalarında belirtildiği gibi, yalnızca ürünü kullanarak buna izin veririz.

Robot süpürgeler tarafından toplanan veriler özellikle istilacı olabilir. Northeastern Üniversitesi’nde robot süpürgeler de dahil olmak üzere Nesnelerin İnterneti cihazlarının güvenlik açıklarını inceleyen bir doktora adayı olan Dennis Giese, “güçlü donanımları, güçlü sensörleri” olduğunu söylüyor. “Ve evinizde dolaşabilirler ve bunu kontrol etmenin hiçbir yolu yoktur.” Bu, özellikle gelişmiş kameralara ve yapay zekaya sahip cihazlar için geçerlidir; örneğin iRobot’un Roomba J7 serisi.
Bu veriler daha sonra, bir gün amacı süpürmenin çok ötesine geçebilecek daha akıllı robotlar inşa etmek için kullanılır. Ancak bu veri kümelerini makine öğrenimi için kullanışlı hale getirmek için, bireysel insanların önce her bir veri parçasına bakması, kategorilere ayırması, etiketlemesi ve başka şekillerde bağlam eklemesi gerekir. Bu işleme veri açıklaması denir.

Kaliforniya Üniversitesi, Santa Barbara’daki teknoloji yönetimi programında yardımcı doçent olan ve robotların arkasındaki insan işini inceleyen Matt Beane, “ Genellikle penceresiz bir odada, bir grup insan oturur ve sadece bir sürü tıklama ve tıklama yaparlar: ‘Evet, bu bir nesne mi, yoksa nesne değil mi?'” diye açıklıyor.
MIT Technology Review ile paylaşılan 15 görüntü, kapsamlı bir veri ekosisteminin yalnızca küçük bir dilimi. iRobot, Scale AI ile 2 milyondan fazla görüntü paylaştığını ve diğer veri açıklama platformlarıyla bilinmeyen miktarda daha fazla görüntü paylaştığını
söyledi ; şirket, Scale’in kullandıkları veri açıklama platformlarından yalnızca biri olduğunu doğruladı.
iRobot’un sözcüsü James Baussmann, bir e-postada şirketin “kişisel verilerin güvenli bir şekilde ve yürürlükteki yasalara uygun şekilde işlenmesini sağlamak için her türlü önlemi aldığını” ve MIT Technology Review ile paylaşılan görüntülerin “iRobot ile bir görüntü açıklama hizmeti sağlayıcısı arasındaki yazılı bir gizlilik sözleşmesini ihlal ederek paylaşıldığını” söyledi. Görüntüleri şirketle paylaşmamızdan birkaç hafta sonra e-postayla gönderilen bir açıklamada, iRobot CEO’su Colin Angle “iRobot’un görüntüleri sızdıran hizmet sağlayıcıyla ilişkisini sonlandırdığını, konuyu aktif olarak araştırdığını ve gelecekte herhangi bir hizmet sağlayıcı tarafından benzer bir sızıntının önlenmesine yardımcı olmak için önlemler aldığını” söyledi. Şirket, bu önlemlerin ne olduğuyla ilgili ek sorulara yanıt vermedi.

Ancak, nihayetinde bu görüntü kümesi herhangi bir şirketin eylemlerinden daha büyük bir şeyi temsil ediyor. Algoritmaları eğitmek için potansiyel olarak hassas verileri paylaşmanın yaygın ve büyüyen uygulamasını ve tek bir görüntünün alabileceği şaşırtıcı, dünya çapındaki yolculuğu anlatıyorlar; bu durumda, Kuzey Amerika, Avrupa ve Asya’daki evlerden Massachusetts merkezli iRobot’un sunucularına, oradan San Francisco merkezli Scale AI’ya ve son olarak Scale’in dünyanın dört bir yanındaki sözleşmeli veri çalışanlarına (bu durumda, görüntüleri Facebook, Discord ve başka yerlerdeki özel gruplara gönderen Venezuelalı geçici işçiler dahil).
Görüntüler bir araya geldiğinde, çok az tüketicinin farkında olduğu bir veri tedarik zincirini ve kişisel bilgilerin sızabileceği yeni noktaları ortaya koyuyor.
Tüketici Raporları’nda teknoloji politikası direktörü ve Federal Ticaret Komisyonu Teknoloji Araştırma ve Soruşturma Ofisi’nin eski politika direktörü Justin Brookman, “İnsanların ham görüntüleri incelemesi beklenmiyor” diye vurguluyor. iRobot, veri toplayıcılarının özellikle insanların bu görüntüleri görüntüleyeceğinin farkında olup olmadıklarını söylemedi ancak şirket, onay formunun “hizmet sağlayıcıların” bunu açıkça belirttiğini söyledi.
Maryland Üniversitesi İletişim Bölümü ve Bilgi Çalışmaları Fakültesi’nde bilgi bilimci ve profesör olan Jessica Vitak, “Makinelere insanlara davrandığımızdan tam anlamıyla farklı davranıyoruz,” diye ekliyor. “Evimde kamerayla dolaşan birindense, sevimli küçük bir elektrikli süpürgeyi, yani alanımda dolaşan birini kabul etmem çok daha kolay.”
Ve yine de, esasen olan budur. Bu sadece tuvalette sizi izleyen bir robot süpürge değil – bir kişi de bakıyor olabilir.
Robot süpürge devrimi
Robot süpürgeler her zaman bu kadar akıllı değildi.
En eski model olan İsveç yapımı Electrolux Trilobite, 2001 yılında piyasaya çıktı. Duvarları bulmak ve temizlik desenleri çizmek için ultrasonik sensörler kullanıyordu; yanlarındaki ek çarpma sensörleri ve altındaki uçurum sensörleri, nesnelere çarpmasını veya merdivenlerden düşmesini önlemeye yardımcı oluyordu. Ancak bu sensörler arızalıydı ve robotun belirli alanları kaçırmasına veya diğerlerini tekrarlamasına neden oluyordu. Sonuç, bitmemiş ve tatmin edici olmayan temizlik işleriydi.
Ertesi yıl, iRobot benzer temel çarpma sensörlerine ve dönüş sensörlerine dayanan ilk nesil Roomba’yı piyasaya sürdü. Rakibinden çok daha ucuz olan bu ürün, ticari olarak başarılı ilk robot süpürge oldu.
Günümüzde en temel modeller bile benzer şekilde çalışırken, orta sınıf temizleyiciler daha iyi sensörler ve eş zamanlı konumlandırma ve haritalama gibi diğer navigasyon tekniklerini bünyesinde barındırarak odadaki yerlerini bulmalarına ve daha iyi temizleme yolları çizmelerine olanak tanır.
Daha üst düzey cihazlar, yapay zekanın bir alt kümesi olan ve görüntü ve videolardan bilgi çıkarmak için algoritmaları eğiterek insan görüşüne yaklaşan bilgisayar görüşüne ve/veya NASA tarafından kullanılan ve günümüzde piyasadaki en doğru, ancak en pahalı navigasyon teknolojisi olarak kabul edilen lazer tabanlı bir algılama tekniği olan lidar’a doğru ilerledi.
Bilgisayar görüşü yüksek çözünürlüklü kameralara bağlıdır ve bizim sayımımıza göre, yaklaşık bir düzine şirket navigasyon ve nesne tanıma için robot süpürgelerine ön kameralar entegre etti; ayrıca, giderek artan bir şekilde, ev izleme. Bunlara pazar payına göre ilk üç robot süpürge üreticisi dahildir: Pazarın %30’una sahip olan ve 2002’den beri 40 milyondan fazla cihaz satan iRobot; yaklaşık %15’e sahip Ecovacs; ve pazar istihbarat firması Strategy Analytics’e göre yaklaşık %15’e sahip Roborock. Ayrıca Samsung, LG ve Dyson gibi bilindik ev aletleri üreticileri de dahildir. Strategy Analytics’e göre, yalnızca 2021’de Avrupa ve Amerika’da toplamda yaklaşık 23,4 milyon robot süpürge satıldı.
iRobot, en başından itibaren bilgisayarlı görüşe odaklandı ve bu tür yeteneklere sahip ilk cihazı olan Roomba 980, 2015 yılında piyasaya sürüldü. Bu cihaz aynı zamanda iRobot’un Wi-Fi özellikli ilk cihazıydı ve aynı zamanda bir evi haritalayabilen, temizlik stratejisini oda boyutuna göre ayarlayabilen ve kaçınılması gereken temel engelleri belirleyebilen ilk cihazdı.
iRobot’un baş teknoloji sorumlusu Chris Jones, “Bilgisayarlı görüş, robotun etrafındaki dünyanın tüm zenginliğini görmesini sağlıyor” diyor. iRobot’un cihazlarının “yerdeki kablolardan kaçınmasını veya bunun bir kanepe olduğunu anlamasını” sağlıyor.
Ancak robot süpürgelerdeki bilgisayarlı görüşün gerçekten amaçlandığı gibi çalışması için üreticilerin, görebilecekleri şeylerin geniş aralığını yansıtan yüksek kaliteli, çeşitli veri kümeleri üzerinde eğitmeleri gerekir. Pekin merkezli Roborock’un kıdemli Ar-Ge direktörü Wu Erqi, “Ev ortamının çeşitliliği çok zor bir iştir,” diyor. Yol sistemleri “oldukça standarttır,” diyor, bu nedenle otonom araç üreticileri için “şeridin nasıl göründüğünü … [ve] trafik işaretinin nasıl göründüğünü bileceksiniz.” Ancak her evin iç mekanı çok farklıdır.
“Mobilyalar standart değil,” diye ekliyor. “Zeminde ne olacağını bekleyemezsiniz. Bazen orada bir çorap, belki bazı kablolar olur”—ve kablolar ABD ve Çin’de farklı görünebilir.
MIT Technology Review, robot süpürge satan 12 şirketle görüştü veya onlara sorular gönderdi ve bu şirketlerin eğitim verisi toplama zorluğuna farklı şekilde yanıt verdiklerini buldu.
iRobot’un durumunda, görüntü veri setinin %95’inden fazlası, sakinleri iRobot çalışanları veya üçüncü taraf veri satıcıları tarafından işe alınan gönüllüler olan gerçek evlerden geliyor (iRobot bunları tanımlamayı reddetti). Geliştirme cihazlarını kullanan kişiler, iRobot’un cihazlar çalışırken video akışları da dahil olmak üzere veri toplamasına izin vermeyi kabul ediyor ve bu genellikle iRobot’un yaptığı bir açıklamaya göre “katılım teşvikleri” karşılığında oluyor. Şirket bu teşviklerin ne olduğunu belirtmeyi reddetti ve yalnızca “veri toplamanın uzunluğuna ve karmaşıklığına göre” değiştiğini söyledi.
Geriye kalan eğitim verileri, iRobot’un “aşamalı veri toplama” olarak adlandırdığı, şirketin daha sonra kaydettiği modeller oluşturduğu süreçten geliyor.
iRobot ayrıca, insanların şirket sunucularına algoritmalarını iyileştirmek için engellerin belirli görüntülerini göndermeyi seçebildiği uygulaması aracılığıyla eğitim verilerine katkıda bulunma seçeneğini düzenli tüketicilere sunmaya başladı. iRobot, bir müşterinin bu “kullanıcı-döngüde” eğitimine katılması durumunda şirketin yalnızca bu belirli görüntüleri aldığını ve başka hiçbir görüntü almadığını söylüyor. Şirket temsilcisi Baussmann, bir e-postada bu tür görüntülerin henüz herhangi bir algoritmayı eğitmek için kullanılmadığını söyledi.
iRobot’un aksine Roborock, “kendi görüntülerini [kendi] laboratuvarlarında ürettiğini” veya “eğitim amaçlarımız için zeminlerdeki nesnelerin görüntülerini yakalamak ve sağlamak üzere özel olarak istenen Çin’deki üçüncü taraf satıcılarla çalıştığını” söyledi. Bu arada, iki adet üst düzey robot süpürge modeli satan Dyson, verileri iki ana kaynaktan topladığını söyledi: “Dyson’ın araştırma ve geliştirme departmanındaki güvenlik iznine sahip ev denemecileri” ve giderek artan şekilde sentetik veya yapay zeka tarafından üretilen eğitim verileri.
MIT Technology Review’in görüştüğü robot vakum şirketlerinin çoğu, makine öğrenme algoritmalarını eğitmek için müşteri verilerini kullanmadıklarını açıkça belirtti. Samsung, verilerini nasıl kaynakladığına ilişkin sorulara yanıt vermedi (ancak veri açıklamaları için Scale AI kullanmadığını yazdı), Ecovacs ise eğitim verilerinin kaynağını “gizli” olarak adlandırdı. LG ve Bosch, yorum taleplerine yanıt vermedi.
“İnsanların birbirlerinden yardım istediğini varsaymalısınız. Politika her zaman bunu yapmamanız gerektiğini söyler, ancak bunu kontrol etmek çok zordur.”
Diğer veri toplama yöntemlerine dair bazı ipuçları, Northeastern’deki ofisi tersine mühendislikle işlediği robot süpürgelerle dolu olan ve bu sayede makine öğrenme modellerine erişebilen IoT hacker’ı Giese’den geliyor. Bazıları, uygun fiyatlı, özellik açısından zengin cihazlar satan Shenzhen merkezli nispeten yeni bir Çin şirketi olan Dreame tarafından üretiliyor.

Giese, Dreame elektrikli süpürgelerinin “AI sunucusu” etiketli bir klasöre ve görüntü yükleme işlevlerine sahip olduğunu buldu. Şirketler genellikle “kamera verileri asla buluta gönderilmiyor ve benzeri şeyler” diyor, diyor Giese, ancak “cihaza erişimim olduğunda, bunun doğru olmadığını temelde kanıtlayabildim.” Aslında hiçbir fotoğraf yüklememiş olsalar bile, “[işlev] her zaman orada.” diye ekliyor.
Giese, Dreame’in ürettiği robot süpürgelerin başka şirketler tarafından yeniden markalandırılarak satıldığını ve bunun da bu uygulamanın başka markalar tarafından da kullanılabileceğinin bir göstergesi olduğunu söylüyor.
Dreame, müşteri cihazlarından toplanan verilerle ilgili e-posta yoluyla gönderilen sorulara yanıt vermedi; ancak MIT Technology Review’in ilk girişiminin ardından şirket, kişisel bilgilerin nasıl toplandığıyla ilgili olanlar da dahil olmak üzere gizlilik politikalarını değiştirmeye ve birden fazla aygıt yazılımı güncellemesi yayınlamaya başladı.
Ancak şirketlerin kendilerinden bir açıklama gelmediği veya iddialarını test etmenin bilgisayar korsanlığı dışında bir yolu olmadığı için, müşterilerden eğitim amaçlı ne topladıklarını kesin olarak bilmek zor.
Verilerimiz neden ve nasıl dünyanın diğer ucuna ulaşıyor?
Makine öğrenme algoritmaları için gereken ham verilerle birlikte, çok fazla işgücüne ihtiyaç duyulur. İşte veri açıklamasının devreye girdiği yer burasıdır. Genç ama büyüyen bir sektör olan veri açıklamasının 2030 yılına kadar 13,3 milyar dolarlık piyasa değerine ulaşması bekleniyor.
Alan, büyük ölçüde, otonom araçlarda kullanılan algoritmaları eğitmek için etiketli verilere olan büyük ihtiyacı karşılamak için harekete geçti. Günümüzde, gelişmekte olan ülkelerde genellikle düşük ücretli sözleşmeli çalışanlar olan veri etiketleyiciler , çevrimiçi olarak “otomatik” olarak kabul ettiğimiz şeylerin çoğuna güç sağlamaya yardımcı oluyor. Gönderileri manuel olarak kategorize ederek ve işaretleyerek İnternet’in en kötülerini sosyal medya akışlarımızdan uzak tutuyor, düşük kaliteli sesleri yazıya dökerek ses tanıma yazılımını iyileştiriyor ve robot süpürgelerin fotoğrafları ve videoları etiketleyerek ortamlarındaki nesneleri tanımasına yardımcı oluyor.
Son on yılda ortaya çıkan sayısız şirket arasında Scale AI pazar lideri haline geldi. 2016’da kurulan şirket, tescilli kitle kaynak platformu Remotasks’te daha az zengin ülkelerdeki uzaktan çalışanlarla ucuz proje veya görev bazlı ücretlerle sözleşme yapma etrafında bir iş modeli oluşturdu.
2020’de Scale orada yeni bir görev yayınladı: Proje IO. Yerden çekilen ve yaklaşık 45 derecelik bir açıyla yukarı doğru açılan görüntüleri içeriyordu ve dünyanın dört bir yanındaki evlerin duvarlarını, tavanlarını ve zeminlerini ve bunların içinde veya üzerinde olan her şeyi gösteriyordu; etiketleyiciler tarafından yüzleri açıkça görülebilen insanlar da dahil.
Etiketleyiciler, gecikmiş ödemelerle ilgili tavsiyeleri paylaşmak, en iyi ücretli ödevleri konuşmak veya zor nesneleri etiketleme konusunda yardım talep etmek için kurdukları Facebook, Discord ve diğer gruplarda Proje IO’yu tartıştılar.
iRobot, bu gruplarda yayınlanan ve daha sonra MIT Technology Review’a gönderilen 15 görüntünün kendi cihazlarından geldiğini doğruladı ve bunların çekildiği belirli tarihleri (Haziran ve Kasım 2020 arasında), geldikleri ülkeleri (Amerika Birleşik Devletleri, Japonya, Fransa, Almanya ve İspanya) ve görüntüleri üreten cihazların seri numaralarını listeleyen bir elektronik tablo paylaştı. Ayrıca, her cihazın kullanıcısı tarafından bir onay formu imzalandığını belirten bir sütun paylaştı. (Scale AI, 15 görüntüden 13’ünün “iRobot ile iki yıl önce üzerinde çalıştığı bir Ar-Ge projesinden” geldiğini doğruladı ancak diğer iki görüntünün kökenlerini açıklamayı veya bunlar hakkında ek bilgi vermeyi reddetti.)
iRobot, sosyal medya gruplarında görsel paylaşmanın Scale’in kendisiyle olan anlaşmalarını ihlal ettiğini söylerken, Scale ise bu görselleri paylaşan sözleşmeli çalışanların kendi anlaşmalarını ihlal ettiğini söylüyor.
“Altta yatan sorun, yüzünüzün değiştiremeyeceğiniz bir şifre gibi olmasıdır. Birisi yüzünüzün ‘imzasını’ bir kez kaydettikten sonra, sizi fotoğraflarda veya videolarda bulmak için bunu sonsuza dek kullanabilir.”
Ancak bu tür eylemleri kitle kaynaklı platformlarda denetlemek neredeyse imkansızdır.
Sözleşmeli çalışanlara da bağlı olan bir Scale rakibi olan Hive’ın CEO’su Kevin Guo’ya, veri etiketleyicilerinin sosyal medyada içerik paylaştığının farkında olup olmadığını sorduğumda, açık sözlü oluyor. “Bunlar dağıtılmış çalışanlar,” diyor. “İnsanların … birbirlerinden yardım istediklerini varsaymalısınız. Politika her zaman bunu yapmamanız gerektiğini söylüyor, ancak bunu kontrol etmek çok zor.”
Bu, belirli bir işi üstlenip üstlenmemeye karar vermenin hizmet sağlayıcısına bağlı olduğu anlamına gelir. Guo, Hive için “iş gücümüz göz önüne alındığında hassas verileri etkili bir şekilde korumak için doğru kontrollerin yerinde olduğunu düşünmüyoruz” diyor. Hive’ın hiçbir robot süpürge şirketiyle çalışmadığını da ekliyor.
Princeton Üniversitesi Görsel Yapay Zeka Laboratuvarı’nın baş araştırmacısı ve AI4All grubunun kurucu ortağı Olga Russakovsky, “[Görüntülerin] bir kitle kaynak platformunda paylaşılmış olması benim için biraz şaşırtıcı,” diyor. “İnsanların sıkı gizlilik anlaşmaları altında” ve “şirket bilgisayarlarında” olduğu şirket içi etiketlemenin, verileri çok daha güvenli tutacağını belirtiyor.
Başka bir deyişle, uzaklardaki veri açıklayıcılarına güvenmek, verileri korumak için güvenli bir yol değildir. “Müşterilerden aldığınız verileriniz olduğunda, normalde erişim koruması olan bir veritabanında bulunur,” diyor önde gelen bir bilgisayar görüşü araştırmacısı ve Stanford Üniversitesi’nde doktora öğrencisi olan Pete Warden. Ancak makine öğrenimi eğitimiyle, müşteri verileri “büyük bir partide” birleştirilerek, bunlara erişen “insan çemberi” genişletilir.
iRobot ise eğitim görüntülerinin yalnızca bir alt kümesini veri açıklama ortaklarıyla paylaştığını, hassas bilgi içeren tüm görüntüleri işaretlediğini ve hassas bilgiler tespit edilirse şirketin gizlilik sorumlusuna bildirdiğini söylüyor. Baussmann bu durumu “nadir” olarak nitelendiriyor ve gerçekleştiğinde “görüntü dahil tüm video günlüğünün iRobot sunucularından silindiğini” ekliyor.
Şirket, “Kullanıcının çıplaklık, kısmi çıplaklık veya cinsel ilişki gibi uygunsuz bir pozisyonda olduğu bir görüntü keşfedildiğinde, bu görüntü, söz konusu günlükteki TÜM diğer görüntülerle birlikte silinir.” dedi. Bu işaretlemenin algoritma tarafından otomatik olarak mı yoksa bir kişi tarafından manuel olarak mı yapılacağını veya tuvaletteki kadın durumunda bunun neden gerçekleşmediğini açıklamadı.
Ancak iRobot politikası, kişiler küçük olsa bile yüzleri hassas olarak görmüyor.
“Robotlara insanlardan ve insan görüntülerinden kaçınmayı öğretmek için” -gizlilik konusunda endişeli müşterilere tanıttığı bir özellik- şirketin “önce robota insanın ne olduğunu öğretmesi gerekiyor” diye açıkladı Baussmann. “Bu anlamda, bir modeli eğitmek için önce insanlardan veri toplamak gerekiyor.” Bunun anlamı, yüzlerin bu verilerin bir parçası olması gerektiğidir.
Ancak Arlington’daki Teksas Üniversitesi’nde Robotik Görme Laboratuvarı’nı yöneten bilgisayar bilimleri profesörü William Beksi’ye göre, algoritmaların insanları tespit edebilmesi için yüz görüntülerine ihtiyaç olmayabilir: İnsan dedektörü modelleri, insanları “sadece bir insanın ana hatlarına (siluetine) dayanarak” tanıyabilir.
Beksi, “Büyük bir şirket olsaydınız ve gizlilik konusunda endişeleriniz olsaydı, bu görüntüleri önceden işleyebilirdiniz” diyor. Örneğin, insan yüzlerini cihazdan çıkmadan önce ve “birisine not düşmeleri için vermeden önce” bulanıklaştırabilirdiniz.
“Biraz özensiz görünüyor,” diye sonlandırıyor, “özellikle de videolarda küçüklerin kaydedilmesi.”
Tuvaletteki kadın örneğinde, bir veri etiketleyicisi yüzünün üzerine siyah bir daire yerleştirerek mahremiyetini korumaya çalıştı. Ancak insanların yer aldığı diğer hiçbir görüntüde kimlikler, veri etiketleyicileri, Scale AI veya iRobot tarafından gizlenmedi. Buna yerde yatan genç çocuğun görüntüsü de dahildir.
Baussmann, iRobot’un “bu insanların kimliğini” “görüntülerden tüm tanımlayıcı bilgileri ayırarak” koruduğunu, böylece “görüntü kötü niyetli biri tarafından ele geçirildiğinde, görüntüdeki kişiyi tanımlamak için geriye doğru haritalama yapamayacağını” açıkladı.
Ancak yüzleri yakalamak özünde gizliliği ihlal eden bir şeydir, diyor Warden. “Temel sorun, yüzünüzün değiştiremeyeceğiniz bir parola gibi olmasıdır,” diyor. “Birisi yüzünüzün ‘imzasını’ kaydettikten sonra, sizi fotoğraflarda veya videolarda bulmak için sonsuza dek kullanabilir.”
Ayrıca, 2013 ile 2017 yılları arasında FTC Tüketici Koruma Bürosu’nun direktörlüğünü yapmış bir gizlilik avukatı olan Jessica Rich, “yasa koyucular ve gizlilikteki uygulayıcılar, yüzler de dahil olmak üzere biyometrik verileri hassas bilgi olarak görecektir” diyor. Özellikle kamerada herhangi bir küçük yakalanmışsa bu durum geçerlidir, diye ekliyor: “Çalışandan [veya test edenlerden] onay almak, çocuktan onay almakla aynı şey değildir. Çalışan, diğer bireyler hakkında veri toplanmasına onay verme kapasitesine sahip değildir – karışmış gibi görünen çocuklardan bahsetmiyorum bile.” Rich, bu yorumlarda belirli bir şirkete atıfta bulunmadığını söylüyor.
Sonuç olarak, gerçek sorun tartışmasız bir şekilde veri etiketleyicilerinin görüntüleri sosyal medyada paylaşması değil . Bunun yerine, bu tür bir AI eğitim setinin (özellikle yüzleri tasvir eden bir setin) çoğu insanın anladığından çok daha yaygın olduğunu belirtiyor, yıllardır veri açıklama şirketleri tarafından sözleşmeli dağıtılmış çalışanlarla görüşmeler yapan sosyolog ve bilgisayar bilimcisi Milagros Miceli. Miceli, benzer görüntüleri aynı düşük bakış açılarından çekilmiş ve bazen insanları çeşitli soyunma aşamalarında gösteren birden fazla etiketleyiciyle görüşen bir araştırma ekibinin parçasıydı.
Veri etiketleyicileri bu çalışmayı “gerçekten rahatsız edici” buldular diye ekliyor.
Sürpriz: Bunu kabul etmiş olabilirsiniz
Robot süpürge üreticileri, cihaz üzerindeki kameraların sunduğu artan gizlilik risklerinin farkındadır. iRobot’un CTO’su Jones, “Bilgisayarlı görüşe yatırım yapma kararı verdiğinizde, gizlilik ve güvenlik konusunda çok dikkatli olmanız gerekir” diyor. “Bu avantajı ürüne ve tüketiciye veriyorsunuz, ancak aynı zamanda gizliliği ve güvenliği en önemli öncelik olarak ele almalısınız.”
Aslında iRobot, MIT Technology Review’a müşteri cihazlarında şifreleme kullanma, güvenlik açıklarını düzenli olarak yamalama, şirket içi çalışanların bilgilere erişimini sınırlama ve izleme ve müşterilere topladığı verilerle ilgili ayrıntılı bilgi sağlama gibi birçok gizlilik ve güvenlik koruma önlemi uyguladığını söylüyor.
Ancak şirketlerin gizlilikten bahsetme biçimleri ile tüketicilerin bunu anlama biçimleri arasında büyük bir uçurum var.
Örneğin, tüketici cihazlarını hem gizlilik hem de güvenlik açısından inceleyen Mozilla’nın “*Privacy Not Included” projesinin baş araştırmacısı Jen Caltrider, gizliliği güvenlikle karıştırmanın kolay olduğunu söylüyor. Veri güvenliği, bir ürünün fiziksel ve siber güvenliğini veya bir saldırıya veya izinsiz girişe karşı ne kadar savunmasız olduğunu ifade ederken, veri gizliliği şeffaflıkla ilgilidir; şirketlerin sahip olduğu verileri, nasıl kullanıldığını, neden paylaşıldığını, saklanıp saklanmadığını ve ne kadar süreyle saklandığını ve bir şirketin başlangıçta ne kadar veri topladığını bilmek ve kontrol edebilmek.
Caltrider, ikisini birleştirmenin kullanışlı olduğunu ekliyor çünkü 2017’de ürünleri izlemeye başladığından beri “güvenlik iyileşirken gizlilik çok daha kötüleşti.” “Cihazlar ve uygulamalar artık çok daha fazla kişisel bilgi topluyor” diyor.
Şirket temsilcileri bazen, veriyi “paylaşmak” ve satmak arasındaki ayrım gibi, gizliliği nasıl ele aldıklarını uzman olmayanlar için özellikle zor bir hale getiren ince farklar da kullanırlar. Bir şirket verilerinizi asla satmayacağını söylediğinde, bu onu analiz için kullanmayacağı veya başkalarıyla paylaşmayacağı anlamına gelmez.
Veri toplamanın bu kapsamlı tanımları, şirketlerin belirsiz bir şekilde ifade edilmiş gizlilik politikaları kapsamında sıklıkla kabul edilebilir; bunların hemen hepsi, verilerin “ürün ve hizmetleri iyileştirme” amaçlarıyla kullanılmasına izin veren bir dil içeriyor; Rich bu dilin “temelde her şeye izin verecek” kadar geniş olduğunu söylüyor.
“Geliştiriciler geleneksel olarak güvenlik işlerinde çok iyi değillerdir.” Onların tutumu “İşlevselliği elde etmeye çalış ve işlevsellik çalışıyorsa ürünü gönder. Sonra da skandallar ortaya çıkar.” olur.
Gerçekten de, MIT Technology Review 12 robot süpürge gizlilik politikasını inceledi ve iRobot’unki de dahil olmak üzere hepsi “ürün ve hizmetleri iyileştirme” konusunda benzer ifadeler içeriyordu. MIT Technology Review’in yorum için ulaştığı şirketlerin çoğu, “ürün iyileştirmenin” makine öğrenme algoritmalarını içerip içermeyeceğine ilişkin sorulara yanıt vermedi. Ancak Roborock ve iRobot içereceğini söylüyor.
Brookman, Birleşik Devletler’in kapsamlı bir veri gizliliği yasasına sahip olmaması nedeniyle (bunun yerine eyalet yasalarının bir karışımına, özellikle de Kaliforniya Tüketici Gizlilik Yasası’na güveniliyor) bu gizlilik politikalarının şirketlerin yasal sorumluluklarını şekillendirdiğini söylüyor. “Birçok gizlilik politikası, biliyorsunuz, verilerinizi seçili ortaklarla veya hizmet sağlayıcılarla paylaşma hakkımızı saklı tutuyoruz” diyor. Bu, tüketicilerin, aşina olsunlar veya olmasınlar, verilerinin ek şirketlerle paylaşılmasını muhtemelen kabul ettikleri anlamına geliyor.
Brookman, şirketlerin tüketicilerden doğrudan veri toplamak için aşmaları gereken yasal engellerin oldukça düşük olduğunu açıklıyor. FTC veya eyalet başsavcıları, “adil olmayan” veya “aldatıcı” uygulamalar varsa devreye girebilir, diyor, ancak bunlar dar bir şekilde tanımlanmış: Brookman, bir gizlilik politikası özellikle “Hey, yüklenicilerin verilerinize bakmasına izin vermeyeceğiz” demediği ve yine de verileri paylaşmadıkları sürece, şirketlerin “muhtemelen aldatma konusunda sorun yaşamadıklarını” söylüyor, ki bu da FTC’nin “tarihsel olarak gizliliği uygulamaya koymasının” ana yoludur. Bu arada, bir uygulamanın adil olmadığını kanıtlamak, zararı kanıtlamak da dahil olmak üzere ek yükümlülükler taşır. “Mahkemeler bu konuda hiçbir zaman gerçekten karar vermedi,” diye ekliyor.
Çoğu şirketin gizlilik politikaları, birkaç istisna dışında, yakalanan görsel-işitsel verilerden bile bahsetmez. iRobot’un gizlilik politikası, yalnızca bir bireyin mobil uygulaması aracılığıyla görüntü paylaşması durumunda görsel-işitsel verileri topladığını belirtir. LG’nin kamera ve yapay zeka destekli Hom-Bot Turbo+ için gizlilik politikası, uygulamasının “profil fotoğrafları, ses kayıtları ve video kayıtları gibi ses, elektronik, görsel veya benzeri bilgiler” dahil olmak üzere görsel-işitsel verileri topladığını açıklar. Her ikisi de kameraya sahip olan Samsung’un lidarlı Jet Bot AI+ Robot Süpürgesi ve Powerbot R7070’in gizlilik politikası, “cihazınızda sakladığınız fotoğraflar, kişiler, metin günlükleri, dokunmatik etkileşimler, ayarlar ve takvim bilgileri gibi bilgileri” ve “bir Hizmeti kontrol etmek veya Müşteri Hizmetleri ekibimizle iletişime geçmek için sesli komutları kullandığınızda sesinizin kayıtlarını” toplayacaktır. Bu arada, Roborock’un gizlilik politikası, şirket temsilcileri MIT Technology Review’a Çin’deki tüketicilerin bunları paylaşma seçeneğine sahip olduğunu söylese de görsel-işitsel verilerden hiç bahsetmiyor.
Şu anda bahçede ot ayıklama robotu satan Tertill adlı bir girişimin başında olan iRobot kurucu ortağı Helen Greiner, şirketlerin tüm bu verileri toplayarak müşterilerinin gizliliğini ihlal etmeye çalışmadıklarını vurguluyor . Sadece daha iyi ürünler üretmeye çalışıyorlar veya iRobot’un durumunda “daha iyi bir temizlik yapmaya” çalışıyorlar diyor.
Yine de, iRobot gibi şirketlerin en iyi çabaları bile gizlilik korumasında açıkça boşluklar bırakıyor. IoT korsanı Giese, “Bu kötü niyetli bir şey değil, sadece yetersizlik,” diyor. “Geliştiriciler geleneksel olarak güvenlik işlerinde çok iyi değiller.” Onların tutumu “İşlevselliği elde etmeye çalış ve işlevsellik çalışıyorsa ürünü gönder” oluyor.
“Ve sonra skandallar ortaya çıkıyor” diye ekliyor.
Robot süpürgeler sadece bir başlangıç
Verilere olan iştah önümüzdeki yıllarda daha da artacak. Elektrikli süpürgeler, hayatlarımızda hızla yaygınlaşan bağlı cihazların sadece küçük bir alt kümesidir ve robot elektrikli süpürgelerdeki en büyük isimler (iRobot, Samsung, Roborock ve Dyson dahil) otomatik zemin temizliğinden çok daha büyük hedefler hakkında seslerini yükseltmektedir. Ev robotları da dahil olmak üzere robotik, uzun zamandır gerçek ödül olmuştur.
O zamanlar iRobot’ta teknolojiden sorumlu kıdemli başkan yardımcısı olan Mario Munich’in 2018’de şirketin hedeflerini nasıl açıkladığını düşünün. Şirketin ilk bilgisayarlı görüşlü vakumu olan Roomba 980 hakkında yaptığı bir sunumda , cihazın bakış açısından alınan görüntüleri gösterdi; bunların arasında bir masa, sandalyeler ve taburelerin bulunduğu bir mutfak da vardı; bunların yanında robotun algoritmaları tarafından nasıl etiketleneceği ve algılanacağı da vardı. Munich, “Sorun vakumlamada değil. Sorun robotta,” diye açıkladı. “Robotun işleyişini değiştirebilmek için ortamı bilmek istiyoruz.”
Bu daha büyük görev, Scale’in veri açıklayıcılarından etiketlemeleri istenen şeylerde açıkça görülüyor: kaçınılması gereken yerdeki öğeler değil (iRobot’un desteklediği bir özellik), “dolap”, “mutfak tezgahı” ve “raf” gibi, Roomba J serisi cihazın çalıştığı tüm alanı tanımasına yardımcı olan öğeler.
Robot süpürgeler üreten şirketler, bizi robotik destekli bir geleceğe yaklaştıracak diğer özelliklere ve cihazlara yatırım yapmaya başladı bile. En son Roombas, Nest ve Alexa aracılığıyla sesle kontrol edilebiliyor ve evdeki 80’den fazla farklı nesneyi tanıyor. Bu arada, Ecovacs’ın Deebot X1 robot süpürgesi, şirketin tescilli ses asistanını entegre etti ve Samsung, insanlara eşlik etmek için “yoldaş robotlar” geliştiren birkaç şirketten biri. RX2 Scout Home Vision’ı satan Miele, kamera destekli akıllı fırını gibi diğer akıllı cihazlara odaklandı.
Ayrıca, iRobot’un Amazon tarafından 1,7 milyar dolara satın alınması işlemi gerçekleşirse (akıllı ev pazarındaki rekabet üzerindeki birleşmenin etkisini değerlendiren FTC’nin onayı beklenirse), Roomba’ların Amazon’un gelecekteki her zaman açık akıllı ev vizyonuna daha da entegre olması muhtemel.
Belki de şaşırtıcı olmayan bir şekilde, kamu politikası veri gizliliğine ilişkin artan kamu endişesini yansıtmaya başlıyor. 2018’den 2022’ye kadar, Kaliforniya Tüketici Gizlilik Yasası ve Illinois Biyometrik Bilgi Gizlilik Yasası gibi gizlilik korumalarını değerlendiren ve geçiren eyaletlerde belirgin bir artış oldu. Federal düzeyde, FTC zararlı ticari gözetim ve gevşek veri güvenliği uygulamalarına karşı yeni kurallar düşünüyor – eğitim verilerinde kullanılanlar dahil. İki durumda, FTC, yapay zekayı eğitmek için müşteri verilerinin gizli kullanımına karşı harekete geçti ve nihayetinde Weight Watchers International ve fotoğraf uygulaması geliştiricisi Everalbum şirketlerini hem toplanan verileri hem de bunlardan oluşturulan algoritmaları silmeye zorladı.
Yine de, bu parça parça çabaların hiçbiri büyüyen veri açıklama pazarını ve dünyanın dört bir yanına yayılmış şirketlerin çoğalmasını veya küresel çapta geçici işçilerle sözleşmeler yapmasını ele almıyor; bu şirketler çoğunlukla veri koruma yasaları daha da az olan ülkelerde, çok az denetimle faaliyet gösteriyor.
Bu yaz Greiner ile konuştuğumda, kişisel olarak iRobot’un gizlilik üzerindeki etkileri konusunda endişeli olmadığını söyledi; ancak bazı insanların neden farklı hissedebileceğini anlamıştı. Sonuç olarak, gizliliği tüketici tercihi açısından çerçevelendirdi: Gerçek endişeleri olan herkes o cihazı satın alamazdı.
“Herkesin kendi gizlilik kararlarını vermesi gerekiyor,” dedi bana. “Ve size şunu söyleyebilirim ki, insanlar çoğunlukla, uygun bir fiyat noktasında sunulduğu sürece özelliklere sahip olma kararını veriyor.”
Ancak herkes bu çerçeveye katılmıyor, kısmen de tüketicilerin tam olarak bilgilendirilmiş seçimler yapmasının çok zor olması nedeniyle. Maryland Üniversitesi bilgi bilimcisi Vitak, rızanın imzalanacak bir “kağıt parçası” veya göz gezdirilecek bir gizlilik politikasından daha fazlası olması gerektiğini söylüyor.
Gerçek bilgilendirilmiş onam, “kişinin prosedürü tam olarak anlaması, riskleri tam olarak anlaması… bu risklerin nasıl azaltılacağını ve… haklarının ne olduğunu anlaması” anlamına gelir, diye açıklıyor. Ancak bu nadiren kapsamlı bir şekilde gerçekleşir; özellikle de şirketler bir düğmeye basarak temiz zeminler vaat eden sevimli robot yardımcıları pazarladığında.
Not : Bu araştırmanın birkaç yıl önce yapıldığını ve bu verilerin daha da büyük boyutlara ve kullanım alanına ulaştığını da göz ardı etmeyeniniz.
Aylin Guo tarafından MIT Technology Review`de 19 Aralık 2022 yayınlanmıştır.
Bu makaleyi ilginç buldunuz mu? Bizi Twitter İnstagram ve LinkedIn sayfalarımızdan takip edebilirsiniz. Özel içeriklerimizi okumak için lütfen Abone olunuz.